
2025年,全球AI大模型赛道硝烟弥漫,以ChatGPT、Grok、DeepSeek和Gemini为首的四大通用语言模型以前所未有的速度迭代,重塑着技术与商业格局。
ChatGPT依托封闭的MoE(Mixture of Experts)架构构建出领先的多模态生态体系,其成熟的API服务体系已占营收的70%,展现出极强的变现能力;Grok则以动态推理网络为核心,主打实时数据响应,并通过与X平台深度捆绑实现商业化突破;DeepSeek以开源模型为基础,针对中文场景深度优化,广泛部署于政企私有化系统中,快速拓展本地市场;Gemini则依托Google Pathways系统,具备强大的算力基座,且已深度集成至Workspace生态,打通了办公与AI应用的边界。
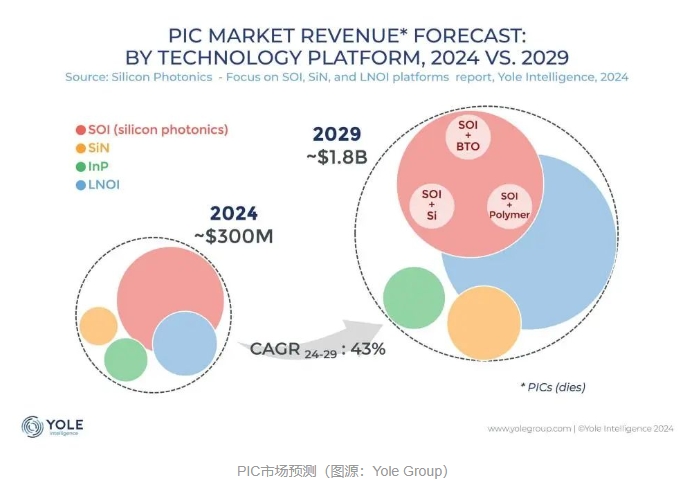
在这场激烈的技术与生态竞速背后,是AI巨头们对算力的持续投入和对高速、低延迟数据交互的迫切需求。这种需求,正驱动着硅光互连技术以前所未有的速度向前发展。根据Yole Group的研究,预计到2029年,硅光集成芯片(PIC)市场规模将超过8.63亿美元,在2023年至2029年期间的复合年增长率将达到45%。

硅光子技术持续快速发展,其多样化的应用预示着未来巨大的机遇。4月23日至25日,在第三届九峰山论坛暨化合物半导体产业博览会上,“硅光”无疑成为最受瞩目的焦点之一。来自世界各地的与会专家学者、产业界人士纷纷聚焦这一前沿技术,探讨其在应对AI时代算力挑战中的关键作用与未来潜力。而更加欣喜的是,中国在硅光子学领域取得了显著进步,并力争成为全球领先者。
业界共识:光互连在AI时代优势尽显 “相较于传统电互连方案,光互连在高速率、低延时和低功耗的长距离数据传输方面展现出无可比拟的优势。”中国科学院半导体研究所助理研究员谢毓俊指出。 华中科技大学三位资深学者对光通信与光计算领域的前沿趋势有着深刻洞察。华中科技大学光学与电子信息学院党委书记、未来技术学院执行院长唐明指出,光电融合集成有望结合光子学和电子学优势,在低功耗和复杂度下实现高性能短距相干光传输,解决智算互连需求。华中科技大学教授邓磊聚焦移动通信,认为模拟光载射频(A-RoF)技术因其高频谱效率、低时延和简化基站结构而受关注。华中科技大学教授董建绩则认为,光子计算凭借高速、低延迟、低功耗和并行性,有望互补电子计算,突破算力和功耗瓶颈,并阐述了“黑盒式”物理训练模型在可重构片上衍射神经网络和大算力并行计算核心处理器中的应用。 光模块,迈向3.2T 在当前的服务器和数据中心中,硅光技术通常是以各种类型的光模块的形式存在的。 华工正源总经理胡长飞指出,当前光模块的主要技术路线包括DPO(Digital Optical Process)、LPO(Low Power Optical)、NPO(New Power Optical)和CPO(Co-Packaged Optics)。其中,基于DSP的DPO技术具备MPI检测和回环功能,便于故障排查。然而,并非所有应用场景都必须采用这些功能。相比之下,LPO和CPO则依赖ASIC芯片实现MPI检测,且CPO因电气通道更短,在功耗方面更具优势。 在光模块领域,集成硅光子(SiPh)模块技术是一个热门的发展方向,它通过将多个光学功能集成到单一的封装中,显著简化了模块的结构。与传统设计相比,集成硅光模块减少了约30%的零部件数量,从而降低了成本,提升了可靠性,并大幅提高了传输效率。同时,基于InP/GaAs化合物半导体的高速光芯片,成为了高速连接的核心驱动。
海思光电子有限公司技术专家曹攀也表示,智算中心网络中高速、大容量的光互联是支撑大模型高效训练的关键技术。他指出,EML(电吸收调制激光器)因其高带宽、良好输出功率、优异消光比、低驱动电压、紧凑尺寸、低功耗和成本效益而成为一种有前景的解决方案。海思光电通过优化芯片设计、器件封装和创新的系统方案,使EML支持的单Lane速率从100Gbps提升至200Gbps。此外,海思光电子的高速EML激光器实现了高达110GHz的3dB带宽,并成功实现了30km标准单模光纤传输。
腾讯光网络架构师封建胜聚焦于智算中心超大规模互连网络对高质量、高带宽和高效能性价比的需求。他指出,具备高性能、大余量等优点的平层光互连技术可成为质量更高、故障率更低的光互连解决方案。
华工正源光子技术有限公司总经理胡长飞表示,如果将AI比作一个人,GPU无疑是AI的“心脏”,LLM(大规模语言模型)则是AI的“大脑”,而数据是AI的“血液”。在这个类比中,光模块便是AI的“动脉”,是确保数据在AI系统中高效流动的核心部件。光模块不仅是AI的赋能者,它的作用日益凸显,特别是在大规模计算和数据传输中,起到了至关重要的作用。在Spine-Leaf-TOR(Top of Rack)架构中,光互联技术可以将GPU扩展到上万甚至十万卡的集群。这种高速连接使得AI系统能够在大规模计算中高效工作,为高性能计算提供了强有力的支撑。
总的来说,光模块的技术演进路径清晰可见:逐渐从当前的单波长100G、400G、800G DR4/DR8技术,逐步发展至单波长200G、400G 3.2T DR8/2xFR4技术,以及共封装(CPO)单波长100G、200G的MRM DR/FR Trx技术。此次九峰山论坛上关于硅光技术的深入探讨,充分展现了这一前沿技术在应对AI大模型时代算力挑战中的核心地位。从关键器件如硅基激光器的突破,到系统级的创新如模拟光载射频和光电融合集成,再到新兴应用如光子计算和硅光子激光雷达,中国乃至全球的科研机构和产业界都在积极探索硅光的无限潜力。
可以预见,随着AI技术的持续发展和对算力需求的不断攀升,硅光互连技术将迎来更加广阔的发展空间和更多的创新机遇,成为支撑下一代信息基础设施的关键力量。然而,正如与会专家所指出的,要实现硅光技术的大规模应用,仍需在材料、工艺、设计和生态建设等方面持续投入和创新,攻克现有瓶颈,最终实现高性能、低成本、高可靠性的光互连解决方案,赋能AI时代的蓬勃发展。本文引用自:https://36kr.com/p/3270534215917700